write_file_bom_utf16beのWindows版。
main.cで、
と書く。

実行すると、

こうなる。
UTF-16BEを読み込むread_wtext_file_binary_utf16be_cstdioを作る。
file_utility_cstdio.hで、
と書く。
file_utility_cstdio.cで、
と書く。
cpp_file_utility_cstdio.hで、
と書く。
cpp_file_utility_cstdio.cppで、
と書く。
main.cppで、
と書く。
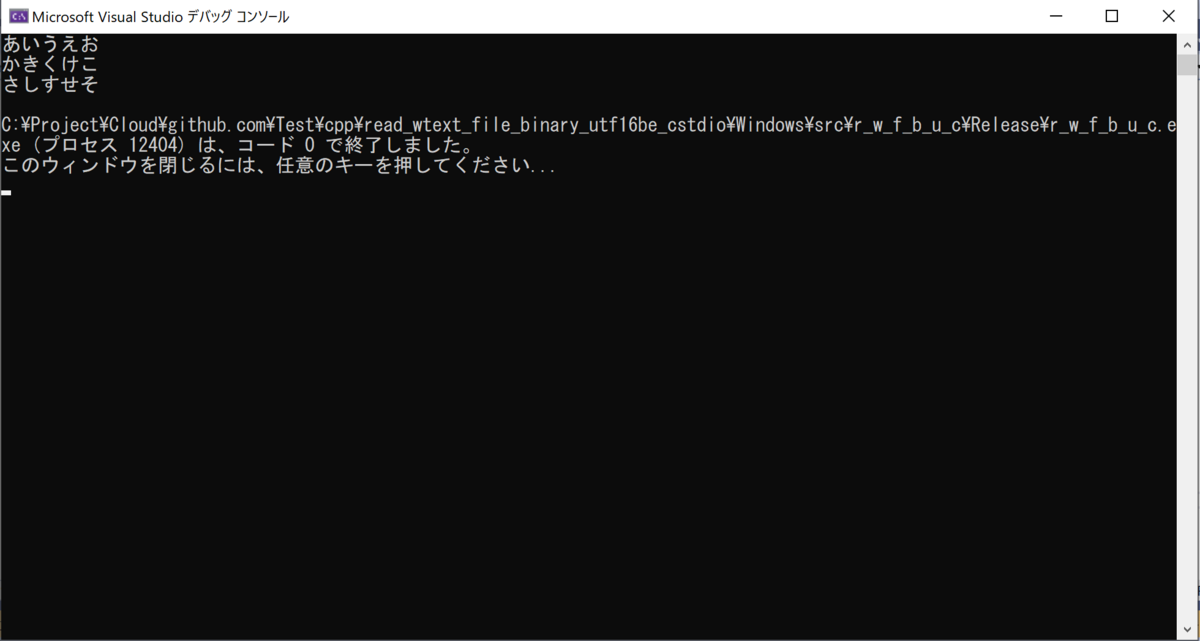
こうなる。
UTF-16BEで書き込むwrite_wtext_file_binary_utf16be_cstdioを作る。
file_utility_cstdio.hで、
と書く。
file_utility_cstdio.cで、
と書く。
cpp_file_utility_cstdio.hで、
と書く。
cpp_file_utility_cstdio.cppで、
と書く。
main.cppで、
と書く。

実行して、

こうなる。
swap_2bytesのWindows版をC++から呼ぶ。
file_utility_cstdio.hは、
と書く。
file_utility_cstdio.cは、
と書く。
main.cppで、
と書く。

こうなる。
Test/cpp/swap_2bytes/call_from_cpp_Windows/src/swap_2bytes at classic · bg1bgst333/Test · GitHub
渡された2つのバイト値(char型変数)を入れ替えるswap_2bytesのWindows版。
main.cで、
と書く。

こうなる。
Test/c/swap_2bytes/Windows/src/swap_2bytes at master · bg1bgst333/Test · GitHub



